您現在的位置是:首頁 >市場 > 2020-11-20 16:45:24 來源:
神經網絡模型在密集圖像中發現小物體
為了自動從科學論文中捕獲重要數據,美國國家標準技術研究院(NIST)的計算機科學家開發了一種方法,可以在圖像數據中包含的密集,低質量繪圖中準確檢測小的幾何對象,例如三角形。NIST模型采用旨在檢測模式的神經網絡方法,在現代生活中具有許多可能的應用。
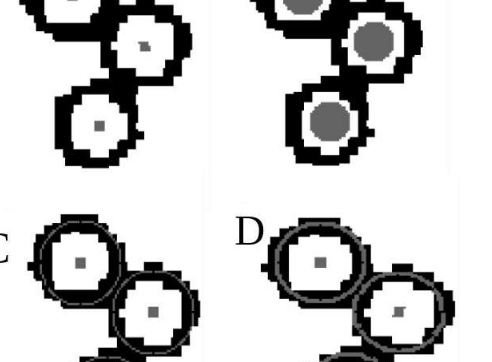
NIST的神經網絡模型在一組定義的測試圖像中捕獲了97%的對象,并將對象的中心定位在手動選擇位置的幾個像素內。
NIST計算機科學家Adele Peskin解釋說:“該項目的目的是恢復期刊文章中丟失的數據。” “但是,小型密集物體檢測的研究還有很多其他應用。物體檢測被廣泛用于圖像分析,自動駕駛汽車,機器檢查等領域,而小型密集物體的檢測尤其困難。找到并分開。”
研究人員從NIST的熱力學研究中心(TRC)的金屬特性數據庫中獲取了可追溯到1900年代初的期刊文章的數據。通常,結果僅以圖形格式顯示,有時是手工繪制,而由于掃描或影印而退化。研究人員希望提取數據點的位置,以恢復原始的原始數據,以進行進一步的分析。到目前為止,這些數據都是手動提取的。
圖像為數據點提供了各種不同的標記,主要是圓形,三角形和正方形(實心和實心),具有不同的大小和清晰度。此類幾何標記通常用于標記科學圖中的數據。在訓練神經網絡之前,使用圖形編輯軟件從文本的子集中手動刪除了可能會錯誤地顯示為數據點的文本,數字和其他符號。
出于多種原因,準確檢測和定位數據標記是一個挑戰。標記的清晰度和確切形狀不一致;它們可能是開放的或充滿的,有時是模糊的或失真的。例如,某些圓形看起來非常圓形,而其他圓形則沒有足夠的像素來完全定義其形狀。另外,許多圖像包含非常密集的重疊圓,正方形和三角形的補丁。
研究人員試圖創建一種網絡模型,以至少與手動檢測一樣準確地識別出繪圖點-在繪圖實際位置的五個像素之內,每邊大小為數千個像素。
如一篇新的期刊論文所述,NIST研究人員采用了最初由德國研究人員開發的用于分析生物醫學圖像的網絡架構,稱為U-Net。首先縮小圖像尺寸以減少空間信息,然后添加要素和上下文信息層以建立精確的高分辨率結果。
為了幫助訓練網絡對標記形狀進行分類并確定其中心,研究人員嘗試了四種使用蒙版標記訓練數據的方法,即為每個幾何對象使用不同大小的中心標記和輪廓。
研究人員發現,向蒙版添加更多信息(例如,更粗的輪廓)可以提高對物體形狀進行分類的準確性,但可以降低在圖中確定其位置的準確性。最后,研究人員結合了幾種模型的最佳方面,以獲得最佳分類和最小的位置誤差。事實證明,更改掩碼是提高網絡性能的最佳方法,它比其他方法(如網絡末端的小更改)更有效。
網絡的最佳性能-定位對象中心的精度達到97%-僅對于圖像點的圖形子集才有可能,這些圖像的原點由非常清晰的圓形,三角形和正方形表示。對于TRC而言,該性能足夠好,可以使用神經網絡從較新的期刊論文中的圖中恢復數據。
盡管NIST研究人員目前尚無后續研究計劃,但神經網絡模型“絕對”可以應用于其他圖像分析問題,Peskin說。
")


")


")



")
")
")
")
")
")
")
")
")