您現在的位置是:首頁 >人工智能 > 2022-01-28 15:02:50 來源:
用于邊緣AI設備的4兆位nvCIM宏
邊緣AI設備是結合人工智能(AI)和邊緣計算技術的系統,正在成為快速發展的物聯網(IoT)生態系統的重要組成部分。這些設備包括智能揚聲器、智能手機、機器人、自動駕駛汽車、無人機和數據處理監控攝像頭。
盡管這些技術在過去幾年中變得越來越先進,但它們中的大多數都表現出有限的能源效率、推理精度和電池壽命。非易失性內存計算(nvCIM)架構是一類新興的方法,可最大限度地減少處理器和內存組件之間的數據移動,有助于顯著降低與復雜AI計算相關的延遲和能耗。
臺積電(TSMC)的研究人員最近開發了一種新的四兆位(4Mb)nvCIM方法,可以幫助提高邊緣AI設備的整體性能。他們提出的架構發表在NatureElectronics上的一篇論文中,將存儲單元與基于互補金屬氧化物半導體(CMOS)技術的外圍電路相結合。
“使用傳統馮諾依曼計算架構為AI應用程序運行的神經網絡的計算延遲和能耗主要由處理元件和內存之間的數據移動主導,從而造成稱為內存墻的性能瓶頸,”Meng-FanChang,進行這項研究的一名研究人員告訴TechXplore。“NvCIM可以通過允許向量矩陣乘法的模擬操作來幫助克服電池供電的AI邊緣設備的內存壁瓶頸,這是推理階段神經網絡中的主要計算操作。”
NvCIM架構可以顯著減少在AI邊緣設備中的處理器和內存之間傳輸的數據量,尤其是當設備在芯片上執行推理和開機操作時。這反過來又可以提高能源效率并延長電池壽命。
Chang和他的同事近10年來一直在開發內存計算(CIM)設備。在他們過去的研究中,他們使用了各種不同的內存組件,包括SRAM、STT-MRAM、PCM、ReRAM和NAND-Flash,來評估最終的性能。
“在過去五年中,我們在頂級微電子會議(ISSCC、IEDM和DAC)上發表了40篇與CIM相關的論文,”Chang解釋說。“我們最近的工作建立在我們對CIM的長期研究的基礎上,其中概述了內存電路設計的技術背景、神經網絡的系統級芯片設計和人工智能算法。”
研究人員創建的新4MbnvCIM架構基于22納米鑄造電阻隨機存取存儲器(ReRAM)設備,也稱為憶阻器。值得注意的是,Chang和他的同事發現它可以執行涉及8位輸入、8位權重和14位輸出的高精度點積運算,且延遲小且能效高。
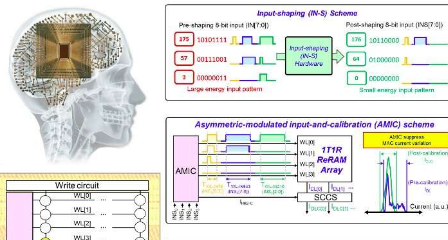
“我們開發了一種基于硬件的輸入整形電路,使用軟硬件協同設計方法來提高能效,而不會降低系統級推理精度,”Chang說。“為了減少計算延遲并提高讀出精度,我們開發了一種非對稱調制輸入和校準(AMIC)方案。”
為了減少他們設備的計算延遲,研究人員構建了一個校準和加權的電流-電壓疊加電路,該電路具有一個2位輸出和全范圍電壓模式檢測放大器。該電路還確保了最高有效位(MSB)的良好讀出良率,從而降低了架構的整體讀出能量。
Chang和他的同事創建的架構可以處理跨各種應用場景的復雜計算任務。此外,與以往提出的其他nvCIM架構相比,它更精確,具有更高的計算吞吐量和更大的內存容量,消耗的能量更少,計算延遲更低。
“我們還專注于軟硬件協同設計,以進一步提高芯片級性能,”Chang說。“用于人工智能和支持人工智能的物聯網(AIoT)應用的現有高級邊緣設備通常采用nvCIM進行斷電數據存儲,以抑制待機模式下的功耗和喚醒期間的輕計算任務。”
未來,這組研究人員開發的架構可用于提高不同邊緣人工智能設備的性能和能源效率,從智能手機到更復雜的機器人系統。除其他外,它可以支持由各種神經網絡模型執行的基本向量矩陣乘法(VMM),包括用于圖像分類的卷積神經網絡(CNN)或深度神經網絡(DNN)。
“電路級別的優化、nvCIM架構的新穎性、規范的改進以及nvCIM宏的性能肯定是我們路線圖上的下一個目標,”Chang補充道。“軟硬件協同設計也是我們未來的研究課題之一,我們的目標是開發對nvCIM友好的神經網絡算法,以進一步最大化nvCIM宏的性能。除此之外,我們的目標是將nvCIM宏和其他必要的數字電路進入下一代人工智能芯片的芯片級系統設計。”
")


")


")



")
")
")
")
")
")
")
")
")