您現在的位置是:首頁 >人工智能 > 2021-04-23 17:43:48 來源:
AdaSearch自適應搜索的連續消除方法
在機器學習的許多任務中,通常希望在給定固定的預先收集的數據集的情況下回答問題。但是,在某些應用中,我們沒有先驗數據; 相反,我們必須收集我們回答感興趣的問題所需的數據。
例如,在環境污染物監測和人口普查式調查中出現這種情況。自己收集數據使我們能夠將注意力集中在最相關的信息來源上。然而,確定哪些信息源將產生有用的測量可能是困難的。此外,當物理代理(例如機器人,衛星,人等)收集數據時,我們必須計劃我們的測量,以便降低與代理的運動相關的成本。我們將這個抽象問題稱為自適應感知。
我們引入了一種新的方法來體現自適應傳感問題,其中機器人必須遍歷其環境以識別感興趣的位置或項目。自適應傳感包括機器人技術中許多經過充分研究的問題,包括快速識別意外污染泄漏和放射源,以及在搜索和救援任務中找到個人。在這樣的設置中,設計一個盡可能快地返回正確解決方案的傳感軌跡通常是至關重要的。
我們關注放射源尋找(RSS)問題,其中無人機必須在其環境中識別最大放射性發射體,其中是用戶定義的參數。RSS是自適應傳感問題的一個特別有趣的例子,由于高度異質的背景噪聲所帶來的挑戰,以及適合于統計置信區間的構建的良好表征的傳感器模型的存在。
我們介紹了AdaSearch,一個用于一般自適應傳感問題的連續消除框架,并在放射源搜索的背景下進行演示。AdaSearch明確保持環境中每個點的排放率的置信區間。使用這些置信區間,算法迭代地識別可能在頂部發射器中的一組候選點,并消除其他點。
體驗式搜索作為多重假設檢驗場景
傳統上,機器人社區已經將具體搜索設想為連續運動規劃問題,其中機器人必須平衡探索其環境與選擇有效軌跡。這推動了將軌跡優化和探索結合到單個目標中的方法,其可以使用后退水平控制進行優化(Hoffman和Tomlin,Bai等人,Marchant和Ramos)。相反,我們考慮一種替代方法,其中我們通過假設檢驗將問題表述為順序最佳行為識別之一。
在順序假設檢驗中,目標是通過迭代收集數據來得出許多單獨問題的結論。給代理一組測量動作,每個動作根據不同的固定分布產生觀察。ñ
代理人的目標是學習這觀察分布的一些預先指定的屬性。例如,在統計“A / B測試”中,測量動作對應于向新客戶顯示產品A或產品B,并記錄他們對該產品的評估。這里,ññ= 2因為只有兩個動作,顯示產品A并顯示產品B.感興趣的屬性是平均優選的產品(下圖中的B)。當我們收集偏好的測量值時,我們會跟蹤樣本平均值以及它們周圍的置信區間,由每個產品的置信區間(LCB)和置信區間上限(UCB)描述。隨著我們收集更多測量值,我們對每個產品的偏好估計值更加自信,因此我們對產品之間的排名也更有信心。這表明產品B優于產品A的結論條件:如果產品B的LCB大于產品A的UCB,那么我們可以得出結論,概率很高,B平均優選為A.
在環境感測的背景下,每個動作可以對應于從給定位置和方向獲取傳感器讀數。通常,代理希望知道哪個單一測量動作產生具有最大平均觀測信號的觀測值,或者哪組動作一起具有最大平均觀測值。為此,代理可以使用先前測量的觀察順序地選擇動作以支持將用于辨別具有最大平均觀察的動作的最具信息性的未來動作。?
乍一看,順序最佳動作識別可能看起來過于抽象,無法在移動的,具體的傳感代理中使用。實際上,代理可以選擇任意任意的測量動作序列,而不考慮潛在的成本 - 例如與改變動作相關的移動時間。然而,順序最佳行動識別的抽象性質也是其最強大的力量。通過以精確的統計語言制定具體的搜索問題,我們開發關于與每個感測動作相關聯的觀察裝置的可操作的置信區間,并確定在感興趣的點可以自信地確定之前仍然需要采取的所有動作的集合。
我們提出的具體搜索方法AdaSearch使用來自順序最佳動作識別和全局軌跡規劃啟發式的置信區間來實現漸近最優的測量復雜度,并有效地攤銷運動成本。
放射源尋求
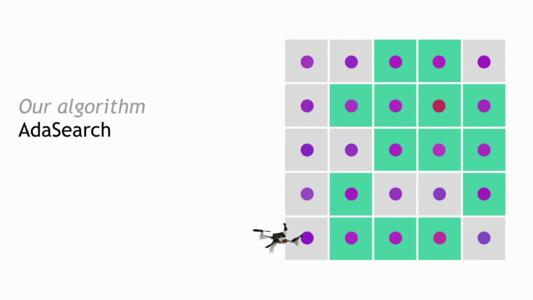
具體而言,我們將在單一來源的放射源尋求問題的背景下呈現AdaSearch。我們將環境建模為平面網格,如下圖所示。只有一個高強度放射性點源(紅點)。然而,定位該光源是困難的,因為傳感器測量被背景輻射(粉紅色點)破壞。通過在網格上方飛行配備有輻射傳感器的四旋翼飛行器來獲得傳感器測量值。目標是設計一系列軌跡,以便從機載傳感器獲得的測量值允許我們盡可能快地消除放射性點源與背景輻射源的歧義。
AdaSearch
我們的算法AdaSearch將全局覆蓋規劃方法與基于假設檢驗的自適應感知規則相結合,以定義這些軌跡。在第一次通過網格時,我們在環境中均勻地進行采樣。
基線
對于一般自適應搜索問題,最流行的方法可能是信息最大化(Bourgault等人)。信息最大化方法根據信息理論標準在被認為有希望的位置收集測量值,并遵循后退水平策略來規劃軌跡。我們將AdaSearch與針對輻射檢測定制的信息最大化版本進行比較:InfoMax。
不幸的是,對于大型搜索空間,該方法的實時計算約束需要近似,例如規劃范圍和軌跡參數化的限制。這些近似可能會導致算法過于貪婪,并且花費太多時間來追蹤虛假線索。
為了消除我們的統計置信區間和全局規劃啟發式(與InfoMax的信息度量和后退時間范圍規劃)的影響之間的歧義,我們實施了一個簡單的全局規劃方法NaiveSearch作為第二個基線。該方法均勻地對網格進行采樣,在每個網格單元處花費相等的時間。
結果
我們實現了所有三種算法,并使用逼真的四旋翼動力學和模擬輻射傳感器讀數,在64 x 64米網格上以4米分辨率模擬了他們在問題上的十個隨機實例化的性能。
在我們的實驗中,我們觀察到AdaSearch通常比NaiveSearch和InfoMax完成得更快。隨著我們增加最大背景輻射水平,AdaSearch的運行時間與NaiveSearch運行時間的比率繼續提高,這與全文中給出的理論界限相匹配。
")









")
")
")
")
")
")
")
")
")