您現在的位置是:首頁 >要聞 > 2021-01-05 08:30:43 來源:
DUAL將AI提升到一個新的水平
韓國DGIST以及UC Irvine和UC San Diego的科學家已經開發出一種計算機體系結構,該體系結構可以更快地處理無監督的機器學習算法,同時與最新的圖形處理單元相比,其能耗要低得多。關鍵是處理數據,并將其以全數字格式存儲在計算機內存中。研究人員在2020年第53屆年度IEEE / ACM國際微體系結構研討會上介紹了一種稱為DUAL的新體系結構。
“今天的計算機應用程序會生成大量需要通過機器學習算法處理的數據,”大邱慶北科技大學(DGIST)的Yeseong Kim說。
強大的“無監督”機器學習包括訓練算法以識別大型數據集中的模式,而無需提供標記示例進行比較。一種流行的方法是聚類算法,它將相似的數據分組為不同的類。這些算法用于各種數據分析,例如在社交媒體上識別虛假新聞,過濾垃圾郵件以及在線檢測或欺詐活動。
科學家一直在研究處理內存中(PIM)的方法來解決這些問題。但是大多數PIM體系結構都是基于模擬的,并且需要模數轉換器和數模轉換器,它們占用了大量的計算機芯片功率和面積。他們還可以在有監督的機器學習中更好地工作,其中包括標記數據集以訓練算法。
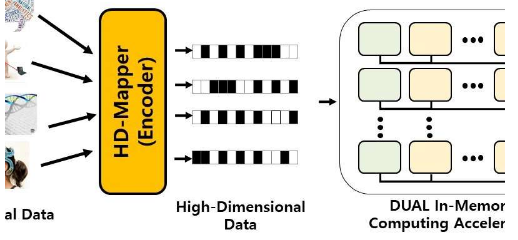
為了克服這些問題,大邱慶北科技大學(DGIST)的Yeseong Kim和他的同事開發了DUAL,DUAL代表基于數字的無監督學習加速。DUAL可以對存儲在計算機內存中的數字數據進行計算。它通過將所有數據點映射到高維空間來工作。想象一下存儲在人腦內許多位置的數據點。
“當今的計算機應用程序會生成大量數據,需要通過機器學習算法進行處理,” Kim說。“但是在傳統內核上運行群集算法會導致高能耗和緩慢處理,因為需要將大量數據從計算機的內存移至執行機器學習任務的處理單元。”
科學家發現,DUAL與最先進的圖形處理單元相比,可以使用各種大規模數據集有效地加速許多聚類算法,并顯著提高了能源效率。研究人員認為,這是第一個可加速無監督機器學習的基于數字的PIM架構。
Kim說:“現有的最新內存計算研究方法致力于通過人工神經網絡來加速有監督的學習算法,這會增加芯片設計成本,并且可能無法保證足夠的學習質量。” “我們證明了將超維和內存計算結合起來可以顯著提高效率,同時提供足夠的精度。”
")





")
")
")
")
")
")
")
")
")
")