您現在的位置是:首頁 >要聞 > 2020-12-17 14:28:47 來源:
研究人員開發出新的算法來訓練機器人
研究實驗室和德克薩斯大學奧斯汀分校的研究人員已經開發了用于機器人或計算機程序的新技術,以學習如何通過與人類教練互動來執行任務。該研究的結果將在2月2日至7日在路易斯安那州新奧爾良舉行的人工智能進步協會會議上進行介紹和發布。
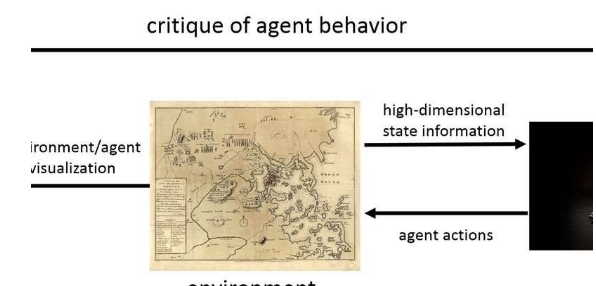
ARL和UT研究人員考慮了一個特定的情況,即人們以批評的形式提供實時反饋。ARL / UT團隊首先由協作者Peter Stone博士(他是德克薩斯州大學奧斯汀分校的教授)與他的前博士生Brad Knox一起作為TAMER引入,或者通過評估強化手動訓練代理,然后,ARL / UT團隊開發了一種新算法叫做Deep TAMER。
它是TAMER的擴展,它使用深度學習-一類機器學習算法,受到大腦的寬松啟發,使機器人能夠通過與人類教練一起在短時間內觀看視頻流來學習如何執行任務的能力。
根據陸軍研究員加勒特·沃內爾(Garrett Warnell)博士的說法,研究小組考慮了一種情況,在這種情況下,人們通過觀察和提供批判來教給特工如何做人,例如“好工作”或“壞工作”,類似于人的訓練方式。狗做個把戲。沃內爾說,研究人員擴展了該領域的早期工作,以便對目前可以通過圖像看到世界的機器人或計算機程序進行這種訓練,這是設計可在現實世界中運行的學習代理的重要的第一步。
人工智能中的許多當前技術要求機器人長時間與環境交互,以學習如何最佳地執行任務。在此過程中,代理可能會執行不僅是錯誤的操作(例如,機器人撞到墻壁上),而且還會發生災難性的操作(例如,機器人在懸崖邊上奔跑)。沃內爾說,人類的幫助將加快代理商的步伐,并幫助他們避免潛在的陷阱。
第一步,研究人員通過將其與15分鐘人工提供的反饋一起使用來證明Deep TAMER的成功,該反饋可訓練代理在Atari保齡球比賽中表現得比人類更好。人工智能中最先進的方法。接受過TAMER訓練的特工表現出超人的能力,不僅擊敗了他們的業余教練,而且平均擊敗了專業的Atari球員。
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")
")