您現在的位置是:首頁 >要聞 > 2020-12-08 08:55:27 來源:
預測神經網絡的擴展能力
盡管研究人員在機器學習方面幫助我們完成了緊縮數字,駕駛汽車和檢測癌癥等工作所取得的所有進步,但我們很少考慮維護大型數據中心使這種工作成為可能的能源消耗。實際上,2017年的一項研究預測,到2025年,連接互聯網的設備將使用世界20%的電力。
機器學習的低效率部分取決于如何創建此類系統。神經網絡通常通過生成初始模型,調整一些參數,再次嘗試然后漂洗和重復來開發。但是這種方法意味著,在任何人都不知道它是否真正起作用之前,在該項目上花費了大量時間,精力和計算資源。
麻省理工學院的研究生喬納森·羅森菲爾德(Jonathan Rosenfeld)將其比作尋求了解重力和行星運動的17世紀科學家。他說,在沒有這樣的理解的情況下,我們今天開發機器學習系統的方式具有有限的預測能力,因此效率很低。
“目前還不是預測一個神經網絡將如何執行給予一定的因素,如模型的形狀,或者它被訓練的數據量的統一,”羅森菲爾德,誰最近研制說,一個新的框架的話題與麻省理工學院計算機科學與人工智能實驗室(CSAIL)的同事們。“我們想通過嘗試理解影響網絡準確性的不同關系來探討是否可以使機器學習向前發展。”
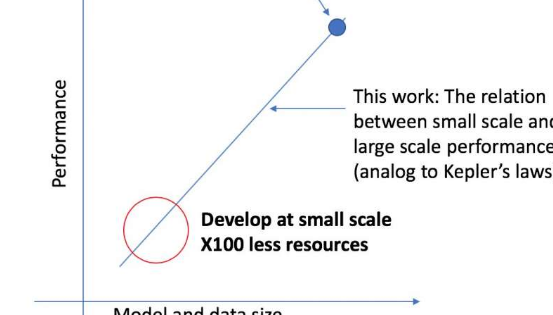
CSAIL團隊的新框架以較小的規模查看給定的算法,并且基于其形狀等因素,可以預測其在較大規模上的性能。這使數據科學家可以確定是否值得繼續投入更多的資源來進一步培訓系統。
麻省理工學院教授尼爾·沙維特(Nir Shavit)說:“我們的方法告訴我們,諸如架構要實現特定目標性能所需的數據量,或者數據與模型大小之間在計算上最有效的折衷”。與Rosenfeld,約克大學前博士研究生Yonatan Belinkov和Amir Rosenfeld合作。“我們認為這些發現對本領域具有深遠的影響,它可以使學術界和行業的研究人員更好地了解開發深度學習模型時必須權衡的不同因素之間的關系,并在有限的計算資源下做到這一點。可供學者使用。”
該框架使研究人員可以使用少50倍的計算能力來準確預測大型模型和數據規模的性能。
團隊關注的深度學習性能方面是所謂的“泛化錯誤”,它是指對真實數據測試算法時產生的錯誤。該團隊利用了模型縮放的概念,該概念涉及以特定方式更改模型形狀以查看其對誤差的影響。
下一步,該團隊計劃探索使特定算法的性能成敗的基礎理論。這包括嘗試其他可能影響深度學習模型訓練的因素。
")
")
")
")

")
")
")
")
")
")
")
")
")
")
")