您現在的位置是:首頁 >市場 > 2020-11-20 16:45:28 來源:
生成手勢以伴隨虛擬座席語音的模型
虛擬助手和機器人正變得越來越復雜,具有交互性并且類似于人。但是,要完全復制人類的交流,人工智能(AI)代理不僅應該能夠確定用戶在說什么并產生適當的響應,還應該模仿他們的說話方式。
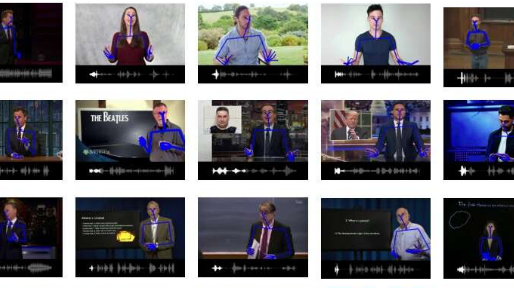
卡內基梅隆大學(CMU)的研究人員最近進行了一項研究,旨在通過產生自然手勢來伴隨他們的語音來改善虛擬助手和機器人與人之間的通信方式。他們的論文預先發表在arXiv上并準備在2020年歐洲計算機視覺會議(ECCV)上發表,介紹了Mix-StAGE,這是一種新模型,可以產生不同風格的共語音手勢,最適合與之對應的語音。演講者和他/她在說什么。
進行這項研究的研究人員之一Chaitanya Ahuja對TechXplore說:“想象一下您正在通過虛擬現實耳機在虛擬空間中與朋友交流的情況。” “耳機只能聽到您的聲音,而看不到您的手勢。我們模型的目標是預測伴隨語音的手勢。”
當人們與他人交流時,他們通常會有獨特的手勢方式。Ahuja和他的同事們希望創建一個可將這些個體差異考慮在內的共語音手勢生成模型,以產生與說話人的聲音和個性相一致的手勢。
Ahuja說:“ Mix-StAGE背后的關鍵思想是為許多不同樣式的手勢學習一個通用的手勢空間。” “此手勢空間包含所有可能的手勢,這些手勢按樣式分組。Mix-StAGE的后半部分學習如何在與輸入語音信號同步的同時預測任何給定樣式的手勢,這一過程稱為樣式轉移。”
Mix-StAGE受過訓練,可以為多個說話者產生有效的手勢,學習每個說話者的獨特風格特征,并產生與這些特征匹配的手勢。另外,該模型可以為另一位演講者的語音生成一個演講者風格的手勢。例如,它可以生成與說話者A所講的手勢相符的手勢,而手勢通常由說話者B使用。
Ahuja解釋說:“與以前的方法要求每種樣式都需要一個單獨的模型不同,我們能夠教一個單一的模型(即涉及較少的內存)來代表許多手勢樣式。” “我們的模型利用手勢樣式之間的相似性,同時記住每個人(即每種樣式)的獨特之處。”
在最初的測試中,由Ahuja和他的同事開發的模型表現出色,可以產生不同樣式的逼真的有效手勢。此外,研究人員發現,隨著他們增加用于訓練Mix-StAGE的揚聲器的數量,其手勢生成準確性大大提高。將來,該模型可以幫助增強虛擬助手和機器人與人類進行交流的方式。
為了訓練Mix-StAGE,研究人員編輯了一個名為Pose-Audio-Transcript-Style(PATS)的數據集,其中包含25個說話的人的語音記錄,總計250個小時以上,并且手勢匹配。該數據集很快將被其他研究團隊用于訓練其他手勢生成模型。
“在我們目前的研究中,當生成手勢時,我們專注于語音的非語言部分(例如,韻律),” Ahuja說。“我們為下一步感到興奮,我們還將語音的言語部分(即語言)作為另一種輸入。假設是語言將有助于特定類型的手勢,例如圖標或隱喻手勢,其中說話的意思可能是最重要的。”
")


")


")



")
")
")
")
")
")
")
")
")